One major design difference between component systems commonly found in the software engineering community and the ones developped by the robotics community is that, in the former, interaction between components is mostly done through messaging and protocols (synchronous or asynchronous RPC) while, in the second one, the dominant model is the one of dataflow (one-way transmission of data samples). The main reason for that difference is that the consensus in the robotics community is to see the component layer as a data processing layer, i.e. a set of intermangled pipelines in which data flows and gets processed, while the software engineering community is more focussed on business processes, in which transmission of information needs to be done through two-way protocols.
In other words: in robotics, when it comes to develop components, data is king. The major implication of that, when one develops a robotic toolchain, is that both tools and components need to be designed so as to handle the issue raising with data, originating from the world and being processed in an asynchronous way.
This subject is very wide, so we will focus on the two most critical points:
- how data should be timestamped, and the tools that Rock provide for that
- how to make components process data in timestamp order (in contrast with in incoming order)
This page will describe the rationale behind these issues. The following pages will go more into the practical side and present Rock’s tools.
Timestamping
Since robotics is all about managing physical systems that evolve in a physical environment, and modify it, the relationship between the data that are being processed and this environment is central to the problem of data processing. Key to that is the ability to associate data temporally: the ability to mark when a particular information was sensed from the physical world. This process is usually referred as ``data timestamping’’.
In the following example, since the two data acquisition pipelines have (tremendously) different processing times, the point cloud generated from the stereo pair and the IMU readings that have originate from the same point in time in the real world are going to reach the pose estimator component at very different times. It is therefore important for the pose estimation component to be able to know their actual order in the real world. This is what data timestamping is meant to achieve: not mark when a particular data structure has been filled, but when the information contained in this data structure was sensed in the real world.
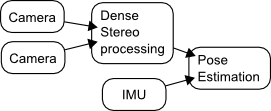
Moreover, at the output of the pose estimator, the generated pose should also be timestamped properly, i.e. mark the time at which the pose estimate was the pose of the robot in the real world. Most estimation algorithms do provide this information (they provide a timestamped best estimate).
It is unfortunately a not so well understood issue. Indeed, a recurrent idea is that the framework itself could timestamp data. Which it could, but only if it had a model of how information propagates through the components – something that to our knowledge none of the mainstream frameworks does.
Tools for data timestamping in Rock are described in the following page
Time-ordered data processing
Very well. If we timestamp data properly, the pose estimation component will know when each data sample is relevant in the real world.
Now, most algorithms require that data gets processed in-order. I.e. they can’t deal with data coming from the past (kalman filters are a good example of that). One therefore needs, at the input of the pose estimation component, to buffer the samples in a separate data structure that will take care of the reordering.
In Rock, this is done through the stream aligner which is described in the following pages